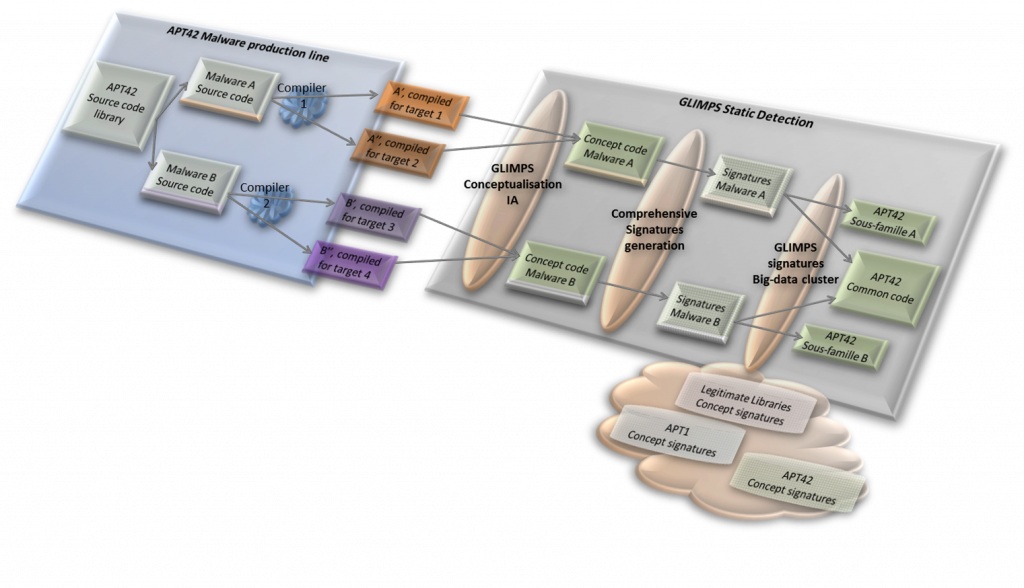
En conceptualisant le code compilé, nous pouvons remonter à un niveau d’abstraction similaire à celui du code source, en s’abstrayant des modifications induites par la compilation, l’architecture cible, etc… Nous pouvons ainsi retrouver la présence de Propriété Intellectuelle d’un groupe d’attaquant dans un fichier, ce qui nous permet de détecter et caractériser immédiatement la menace.
Dans la figure suivante, un groupe d’attaquant, « APT 42 », possède un code « privé ». Une fois utilisé dans plusieurs malwares et plusieurs campagnes, il est très difficile de remonter à ce code commun. Grâce à notre technologie, nous transformons les différents malwares exploités par ce groupe en « Concept Code », et leurs caractéristiques propres étant indépendantes des chaînes de compilation et des architectures utilisées, nous sommes capables d’identifier la présence de code commun entre ces deux branches et d’affirmer que l’attaquant possède nécessairement un code source commun utilisé pour les produire : les deux sous-familles proviennent alors nécessairement de la même entité ! Bien sûr, auparavant, nous avons supprimé tout concept-code associé à du code public (runtimes, codes open-source…) que l’on peut retrouver dans de nombreux malwares.